Li Zichao & Zeng Nanjin WISE IUEC 2016
1.Introduction
In this assignment a neural network model is developed to predict house price. The data of house price and explanatory variables describing almost every aspect of residential homes in Ames, lowa is downloaded from Kaggle.
3 models will be used to predict houses price:
- Only the continuous features
- Continuous features and catagorical features
- Shallow network
The dataset is composed to 1460 row with 81 features, concluding 38 continuous features and 43 categorical features. The variables are listed below,
| variable name | Explanation |
|---|---|
| SalePrice | the property’s sale price in dollars. This is the target variable that you’re trying to predict |
| MSSubClass | The building class |
| MSZoning | The general zoning classification |
| LotFrontage | Linear feet of street connected to property |
| LotArea | Lot size in square feet |
| Street | Type of road access |
| Alley | Type of alley access |
| LotShape | General shape of property |
| LandContour | Flatness of the property |
| Utilities | Type of utilities available |
| LotConfig | Lot configuration |
| LandSlope | Slope of property |
| Neighborhood | Physical locations within Ames city limits |
| Condition1 | Proximity to main road or railroad |
| Condition2 | Proximity to main road or railroad (if a second is present) |
| BldgType | Type of dwelling |
| HouseStyle | Style of dwelling |
| OverallQual | Overall material and finish quality |
| OverallCond | Overall condition rating |
| YearBuilt | Original construction date |
| YearRemodAdd | Remodel date |
| RoofStyle | Type of roof |
| RoofMatl | Roof material |
| Exterior1st | Exterior covering on house |
| Exterior2nd | Exterior covering on house (if more than one material) |
| MasVnrType | Masonry veneer type |
| MasVnrArea | Masonry veneer area in square feet |
| ExterQual | Exterior material quality |
| ExterCond | Present condition of the material on the exterior |
| Foundation | Type of foundation |
| BsmtQual | Height of the basement |
| BsmtCond | General condition of the basement |
| BsmtExposure | Walkout or garden level basement walls |
| BsmtFinType1 | Quality of basement finished area |
| BsmtFinSF1 | Type 1 finished square feet |
| BsmtFinType2 | Quality of second finished area (if present) |
| BsmtFinSF2 | Type 2 finished square feet |
| BsmtUnfSF | Unfinished square feet of basement area |
| TotalBsmtSF | Total square feet of basement area |
| Heating | Type of heating |
| HeatingQC | Heating quality and condition |
| CentralAir | Central air conditioning |
| Electrical | Electrical system |
| 1stFlrSF | First Floor square feet |
| 2ndFlrSF | Second floor square feet |
| LowQualFinSF | Low quality finished square feet (all floors) |
| GrLivArea | Above grade (ground) living area square feet |
| BsmtFullBath | Basement full bathrooms |
| BsmtHalfBath | Basement half bathrooms |
| FullBath | Full bathrooms above grade |
| HalfBath | Half baths above grade |
| Bedroom | Number of bedrooms above basement level |
| Kitchen | Number of kitchens |
| KitchenQual | Kitchen quality |
| TotRmsAbvGrd | Total rooms above grade (does not include bathrooms) |
| Functional | Home functionality rating |
| Fireplaces | Number of fireplaces |
| FireplaceQu | Fireplace quality |
| GarageType | Garage location |
| GarageYrBlt | Year garage was built |
| GarageFinish | Interior finish of the garage |
| GarageCars | Size of garage in car capacity |
| GarageArea | Size of garage in square feet |
| GarageQual | Garage quality |
| GarageCond | Garage condition |
| PavedDrive | Paved driveway |
| WoodDeckSF | Wood deck area in square feet |
| OpenPorchSF | Open porch area in square feet |
| EnclosedPorch | Enclosed porch area in square feet |
| 3SsnPorch | Three season porch area in square feet |
| ScreenPorch | Screen porch area in square feet |
| PoolArea | Pool area in square feet |
| PoolQC | Pool quality |
| Fence | Fence quality |
| MiscFeature | Miscellaneous feature not covered in other categories |
| MiscVal | $Value of miscellaneous feature |
| MoSold | Month Sold |
| YrSold | Year Sold |
| SaleType | Type of sale |
| SaleCondition | Condition of sale |
For raw data, click here.
2.Progamming
Only Continuous Features
We only conclude continuous features as explantory variable in the first model. Using IsolationForest we isolate outliers and rescale the data with function MinMaxScaler.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import itertools
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import rcParams
import matplotlib
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
tf.logging.set_verbosity(tf.logging.INFO)
sess = tf.InteractiveSession()
train = pd.read_csv('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/train.csv')
print('Shape of the train data with all features:', train.shape)
train = train.select_dtypes(exclude=['object'])
print("")
print('Shape of the train data with numerical features:', train.shape)
train.drop('Id',axis = 1, inplace = True)
train.fillna(0,inplace=True)
test = pd.read_csv('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/test.csv')
test = test.select_dtypes(exclude=['object'])
ID = test.Id
test.fillna(0,inplace=True)
test.drop('Id',axis = 1, inplace = True)
print("")
print("List of features contained our dataset:",list(train.columns))
Shape of the train data with all features: (1460, 81)
Shape of the train data with numerical features: (1460, 38)
List of features contained our dataset: ['MSSubClass', 'LotFrontage', 'LotArea', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageYrBlt', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal', 'MoSold', 'YrSold', 'SalePrice']
Isolate outliers:
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples = 100, random_state = 42)
clf.fit(train)
y_noano = clf.predict(train)
y_noano = pd.DataFrame(y_noano, columns = ['Top'])
y_noano[y_noano['Top'] == 1].index.values
train = train.iloc[y_noano[y_noano['Top'] == 1].index.values]
train.reset_index(drop = True, inplace = True)
print("Number of Outliers:", y_noano[y_noano['Top'] == -1].shape[0])
print("Number of rows without outliers:", train.shape[0])
Number of Outliers: 146
Number of rows without outliers: 1314
Rescale the data:
import warnings
warnings.filterwarnings('ignore')
col_train = list(train.columns)
col_train_bis = list(train.columns)
col_train_bis.remove('SalePrice')
mat_train = np.matrix(train)
mat_test = np.matrix(test)
mat_new = np.matrix(train.drop('SalePrice',axis = 1))
mat_y = np.array(train.SalePrice).reshape((1314,1))
prepro_y = MinMaxScaler()
prepro_y.fit(mat_y)
prepro = MinMaxScaler()
prepro.fit(mat_train)
prepro_test = MinMaxScaler()
prepro_test.fit(mat_new)
train = pd.DataFrame(prepro.transform(mat_train),columns = col_train)
test = pd.DataFrame(prepro_test.transform(mat_test),columns = col_train_bis)
Transform the features into a special format that fits for TensorFlow:
# List of features
COLUMNS = col_train
FEATURES = col_train_bis
LABEL = "SalePrice"
# Columns for tensorflow
feature_cols = [tf.contrib.layers.real_valued_column(k) for k in FEATURES]
# Training set and Prediction set with the features to predict
training_set = train[COLUMNS]
prediction_set = train.SalePrice
# Train and Test
x_train, x_test, y_train, y_test = train_test_split(training_set[FEATURES] , prediction_set, test_size=0.33, random_state=42)
y_train = pd.DataFrame(y_train, columns = [LABEL])
training_set = pd.DataFrame(x_train, columns = FEATURES).merge(y_train, left_index = True, right_index = True)
training_set.head()
# Training for submission
training_sub = training_set[col_train]
# Same thing but for the test set
y_test = pd.DataFrame(y_test, columns = [LABEL])
testing_set = pd.DataFrame(x_test, columns = FEATURES).merge(y_test, left_index = True, right_index = True)
Deep neural network for continuous features. The model has 5 hidden layers with respective 500,100,50,25 and 12 units and the function of activation will be Relu.
tf.logging.set_verbosity(tf.logging.ERROR)
regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols, activation_fn = tf.nn.relu, hidden_units=[200, 100, 50, 25, 12])
# Reset the index of training
training_set.reset_index(drop = True, inplace =True)
def input_fn(data_set, pred = False):
if pred == False:
feature_cols = {k: tf.constant(data_set[k].values) for k in FEATURES}
labels = tf.constant(data_set[LABEL].values)
return feature_cols, labels
if pred == True:
feature_cols = {k: tf.constant(data_set[k].values) for k in FEATURES}
return feature_cols
# Deep Neural Network Regressor with the training set which contain the data split by train test split
regressor.fit(input_fn=lambda: input_fn(training_set), steps=2000)
# Evaluation on the test set created by train_test_split
ev = regressor.evaluate(input_fn=lambda: input_fn(testing_set), steps=1)
# Display the score on the testing set
loss_score1 = ev["loss"]
print("Final Loss on the testing set: {0:f}".format(loss_score1))
# Predictions
y = regressor.predict(input_fn=lambda: input_fn(testing_set))
predictions = list(itertools.islice(y, testing_set.shape[0]))
Final Loss on the testing set: 0.002390
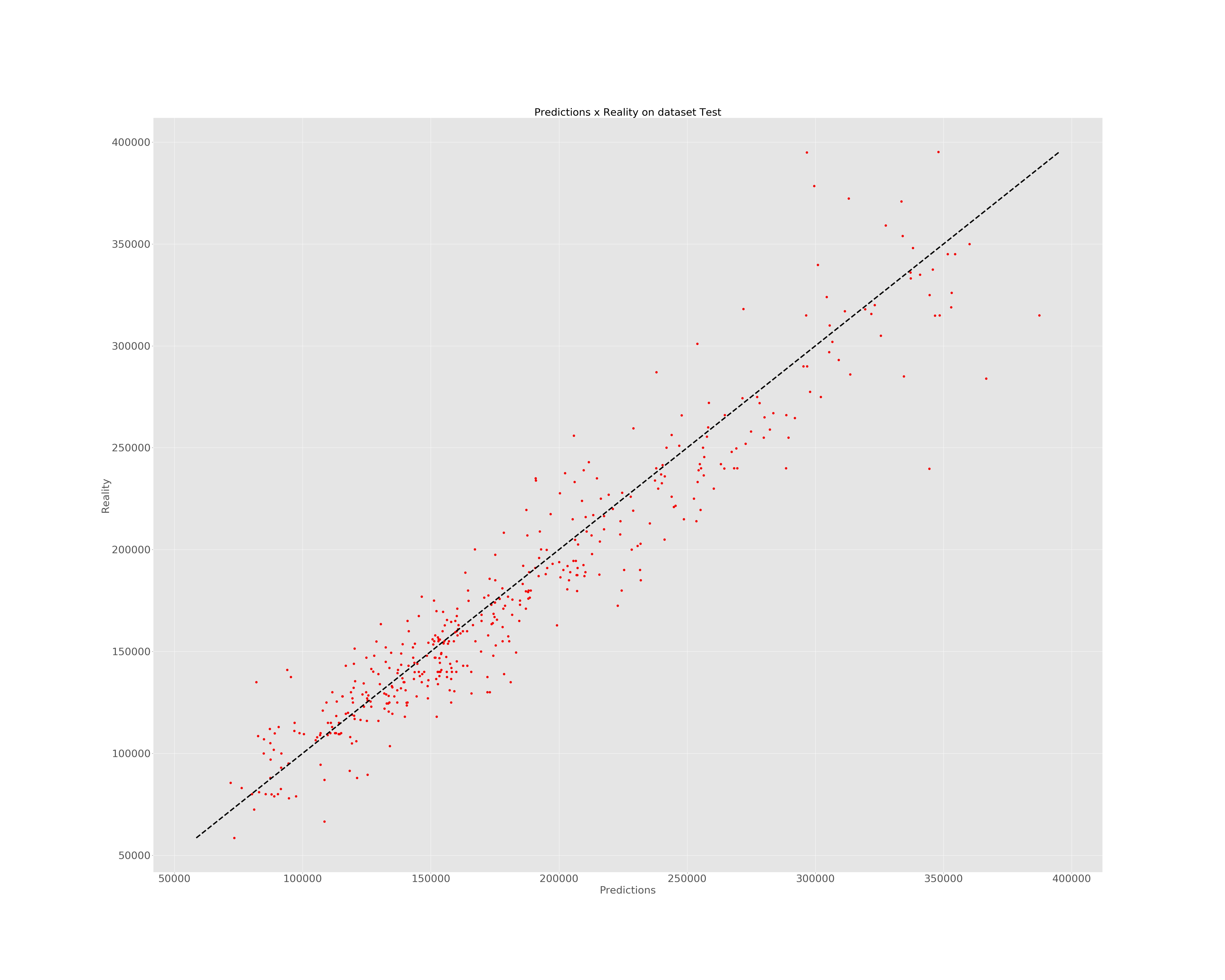
Data submission and an illustration of the different between the reality and the predictions.
predictions = pd.DataFrame(prepro_y.inverse_transform(np.array(predictions).reshape(434,1)),columns = ['Prediction'])
reality = pd.DataFrame(prepro.inverse_transform(testing_set), columns = [COLUMNS]).SalePrice
fig, ax = plt.subplots(figsize=(50, 40))
plt.style.use('ggplot')
plt.plot(predictions.values, reality.values, 'ro')
plt.xlabel('Predictions', fontsize = 30)
plt.ylabel('Reality', fontsize = 30)
plt.title('Predictions x Reality on dataset Test', fontsize = 30)
ax.plot([reality.min(), reality.max()], [reality.min(), reality.max()], 'k--', lw=4)
plt.savefig('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/constat.jpg')
plt.show()
# Submission of result.
y_predict = regressor.predict(input_fn=lambda: input_fn(test, pred = True))
def to_submit(pred_y,name_out):
y_predict = list(itertools.islice(pred_y, test.shape[0]))
y_predict = pd.DataFrame(prepro_y.inverse_transform(np.array(y_predict).reshape(len(y_predict),1)), columns = ['SalePrice'])
y_predict = y_predict.join(ID)
y_predict.to_csv('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/'+name_out + '.csv',index=False)
to_submit(y_predict, "submission_continuous")
Continuous and Catagorical Features
We repeat the process above including all features in the dataset.
# Repeat for continous and catagorical features
train = pd.read_csv('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/train.csv')
train.drop('Id',axis = 1, inplace = True)
train_numerical = train.select_dtypes(exclude=['object'])
train_numerical.fillna(0,inplace = True)
train_categoric = train.select_dtypes(include=['object'])
train_categoric.fillna('NONE',inplace = True)
train = train_numerical.merge(train_categoric, left_index = True, right_index = True)
test = pd.read_csv('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/test.csv')
ID = test.Id
test.drop('Id',axis = 1, inplace = True)
test_numerical = test.select_dtypes(exclude=['object'])
test_numerical.fillna(0,inplace = True)
test_categoric = test.select_dtypes(include=['object'])
test_categoric.fillna('NONE',inplace = True)
test = test_numerical.merge(test_categoric, left_index = True, right_index = True)
# Removie the outliers
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples = 100, random_state = 42)
clf.fit(train_numerical)
y_noano = clf.predict(train_numerical)
y_noano = pd.DataFrame(y_noano, columns = ['Top'])
y_noano[y_noano['Top'] == 1].index.values
train_numerical = train_numerical.iloc[y_noano[y_noano['Top'] == 1].index.values]
train_numerical.reset_index(drop = True, inplace = True)
train_categoric = train_categoric.iloc[y_noano[y_noano['Top'] == 1].index.values]
train_categoric.reset_index(drop = True, inplace = True)
train = train.iloc[y_noano[y_noano['Top'] == 1].index.values]
train.reset_index(drop = True, inplace = True)
col_train_num = list(train_numerical.columns)
col_train_num_bis = list(train_numerical.columns)
col_train_cat = list(train_categoric.columns)
col_train_num_bis.remove('SalePrice')
mat_train = np.matrix(train_numerical)
mat_test = np.matrix(test_numerical)
mat_new = np.matrix(train_numerical.drop('SalePrice',axis = 1))
mat_y = np.array(train.SalePrice)
prepro_y = MinMaxScaler()
prepro_y.fit(mat_y.reshape(1314,1))
prepro = MinMaxScaler()
prepro.fit(mat_train)
prepro_test = MinMaxScaler()
prepro_test.fit(mat_new)
train_num_scale = pd.DataFrame(prepro.transform(mat_train),columns = col_train)
test_num_scale = pd.DataFrame(prepro_test.transform(mat_test),columns = col_train_bis)
train[col_train_num] = pd.DataFrame(prepro.transform(mat_train),columns = col_train_num)
test[col_train_num_bis] = test_num_scale
# List of features
COLUMNS = col_train_num
FEATURES = col_train_num_bis
LABEL = "SalePrice"
FEATURES_CAT = col_train_cat
engineered_features = []
for continuous_feature in FEATURES:
engineered_features.append(
tf.contrib.layers.real_valued_column(continuous_feature))
for categorical_feature in FEATURES_CAT:
sparse_column = tf.contrib.layers.sparse_column_with_hash_bucket(
categorical_feature, hash_bucket_size=1000)
engineered_features.append(tf.contrib.layers.embedding_column(sparse_id_column=sparse_column, dimension=16,combiner="sum"))
# Training set and Prediction set with the features to predict
training_set = train[FEATURES + FEATURES_CAT]
prediction_set = train.SalePrice
# Train and Test
x_train, x_test, y_train, y_test = train_test_split(training_set[FEATURES + FEATURES_CAT] ,
prediction_set, test_size=0.33, random_state=42)
y_train = pd.DataFrame(y_train, columns = [LABEL])
training_set = pd.DataFrame(x_train, columns = FEATURES + FEATURES_CAT).merge(y_train, left_index = True, right_index = True)
# Training for submission
training_sub = training_set[FEATURES + FEATURES_CAT]
testing_sub = test[FEATURES + FEATURES_CAT]
# Same thing but for the test set
y_test = pd.DataFrame(y_test, columns = [LABEL])
testing_set = pd.DataFrame(x_test, columns = FEATURES + FEATURES_CAT).merge(y_test, left_index = True, right_index = True)
training_set[FEATURES_CAT] = training_set[FEATURES_CAT].applymap(str)
testing_set[FEATURES_CAT] = testing_set[FEATURES_CAT].applymap(str)
def input_fn_new(data_set, training = True):
continuous_cols = {k: tf.constant(data_set[k].values) for k in FEATURES}
categorical_cols = {k: tf.SparseTensor(
indices=[[i, 0] for i in range(data_set[k].size)], values = data_set[k].values, dense_shape = [data_set[k].size, 1]) for k in FEATURES_CAT}
# Merges the two dictionaries into one.
feature_cols = dict(list(continuous_cols.items()) + list(categorical_cols.items()))
if training == True:
# Converts the label column into a constant Tensor.
label = tf.constant(data_set[LABEL].values)
# Returns the feature columns and the label.
return feature_cols, label
return feature_cols
# Model
regressor = tf.contrib.learn.DNNRegressor(feature_columns = engineered_features,activation_fn = tf.nn.relu, hidden_units=[200, 100, 50, 25, 12])
categorical_cols = {k: tf.SparseTensor(indices=[[i, 0] for i in range(training_set[k].size)], values = training_set[k].values, dense_shape = [training_set[k].size, 1]) for k in FEATURES_CAT}
# Deep Neural Network Regressor with the training set which contain the data split by train test split
regressor.fit(input_fn = lambda: input_fn_new(training_set) , steps=2000)
DNNRegressor(params={'head': <tensorflow.contrib.learn.python.learn.estimators.head._RegressionHead object at 0x000002A29AC18588>, 'hidden_units': [200, 100, 50, 25, 12], 'feature_columns': (_RealValuedColumn(column_name='MSSubClass', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='LotFrontage', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='LotArea', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='OverallQual', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='OverallCond', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='YearBuilt', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='YearRemodAdd', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='MasVnrArea', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BsmtFinSF1', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BsmtFinSF2', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BsmtUnfSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='TotalBsmtSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='1stFlrSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='2ndFlrSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='LowQualFinSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='GrLivArea', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BsmtFullBath', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BsmtHalfBath', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='FullBath', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='HalfBath', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='BedroomAbvGr', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='KitchenAbvGr', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='TotRmsAbvGrd', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='Fireplaces', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='GarageYrBlt', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='GarageCars', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='GarageArea', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='WoodDeckSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='OpenPorchSF', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='EnclosedPorch', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='3SsnPorch', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='ScreenPorch', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='PoolArea', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='MiscVal', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='MoSold', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _RealValuedColumn(column_name='YrSold', dimension=1, default_value=None, dtype=tf.float32, normalizer=None), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='MSZoning', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18240>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Street', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18F98>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Alley', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18BE0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='LotShape', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18DA0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='LandContour', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18BA8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Utilities', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18CC0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='LotConfig', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC182E8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='LandSlope', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18C18>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Neighborhood', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18978>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Condition1', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18AC8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Condition2', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18908>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BldgType', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18A20>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='HouseStyle', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18898>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='RoofStyle', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC188D0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='RoofMatl', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC189B0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Exterior1st', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC185F8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Exterior2nd', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18940>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='MasVnrType', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18780>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='ExterQual', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC184A8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='ExterCond', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC186A0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Foundation', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18828>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BsmtQual', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18710>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BsmtCond', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18668>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BsmtExposure', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC187B8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BsmtFinType1', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18320>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='BsmtFinType2', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC186D8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Heating', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC183C8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='HeatingQC', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18400>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='CentralAir', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC184E0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Electrical', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18390>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='KitchenQual', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC181D0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Functional', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18160>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='FireplaceQu', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18358>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='GarageType', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18080>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='GarageFinish', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC182B0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='GarageQual', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18048>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='GarageCond', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18128>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='PavedDrive', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18208>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='PoolQC', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18C88>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='Fence', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC180F0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='MiscFeature', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC180B8>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='SaleType', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29AC18438>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True), _EmbeddingColumn(sparse_id_column=_SparseColumnHashed(column_name='SaleCondition', is_integerized=False, bucket_size=1000, lookup_config=None, combiner='sum', dtype=tf.string), dimension=16, combiner='sum', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x000002A29A80DEF0>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, shared_embedding_name=None, shared_vocab_size=None, max_norm=None, trainable=True)), 'optimizer': None, 'activation_fn': <function relu at 0x000002A2F133DA60>, 'dropout': None, 'gradient_clip_norm': None, 'embedding_lr_multipliers': None, 'input_layer_min_slice_size': None})
Calculate score of this model:
ev = regressor.evaluate(input_fn=lambda: input_fn_new(testing_set, training = True), steps=1)
loss_score2 = ev["loss"]
print("Final Loss on the testing set: {0:f}".format(loss_score2))
Final Loss on the testing set: 0.002072
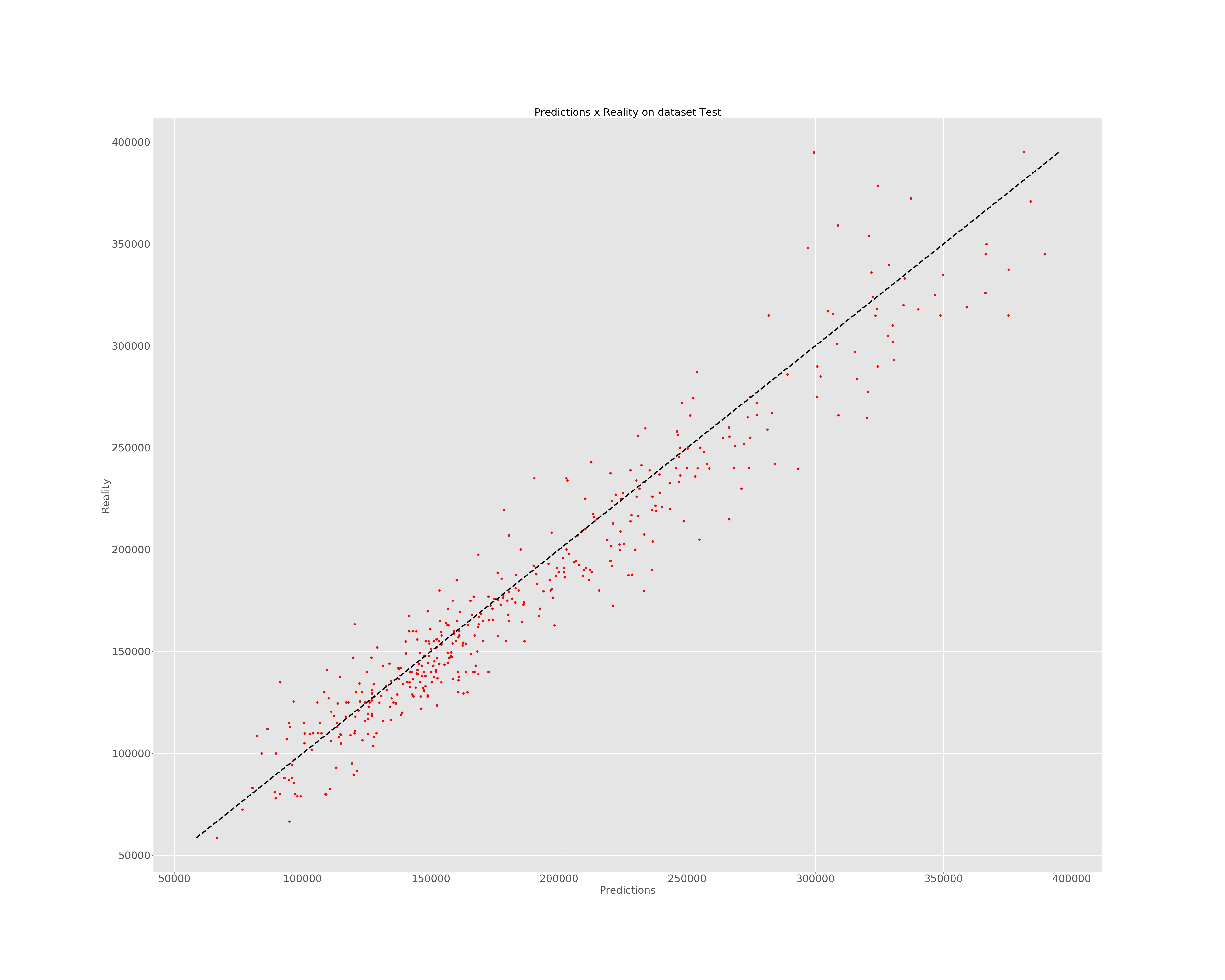
Illustration of predictions:
# Predictions
y = regressor.predict(input_fn=lambda: input_fn_new(testing_set))
predictions = list(itertools.islice(y, testing_set.shape[0]))
predictions = pd.DataFrame(prepro_y.inverse_transform(np.array(predictions).reshape(434,1)))
matplotlib.rc('xtick', labelsize=30)
matplotlib.rc('ytick', labelsize=30)
fig, ax = plt.subplots(figsize=(50, 40))
plt.style.use('ggplot')
plt.plot(predictions.values, reality.values, 'ro')
plt.xlabel('Predictions', fontsize = 30)
plt.ylabel('Reality', fontsize = 30)
plt.title('Predictions x Reality on dataset Test', fontsize = 30)
ax.plot([reality.min(), reality.max()], [reality.min(), reality.max()], 'k--', lw=4)
plt.savefig('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/con_cat.jpg')
plt.show()
y_predict = regressor.predict(input_fn=lambda: input_fn_new(testing_sub, training = False))
to_submit(y_predict, "submission_cont_categ")
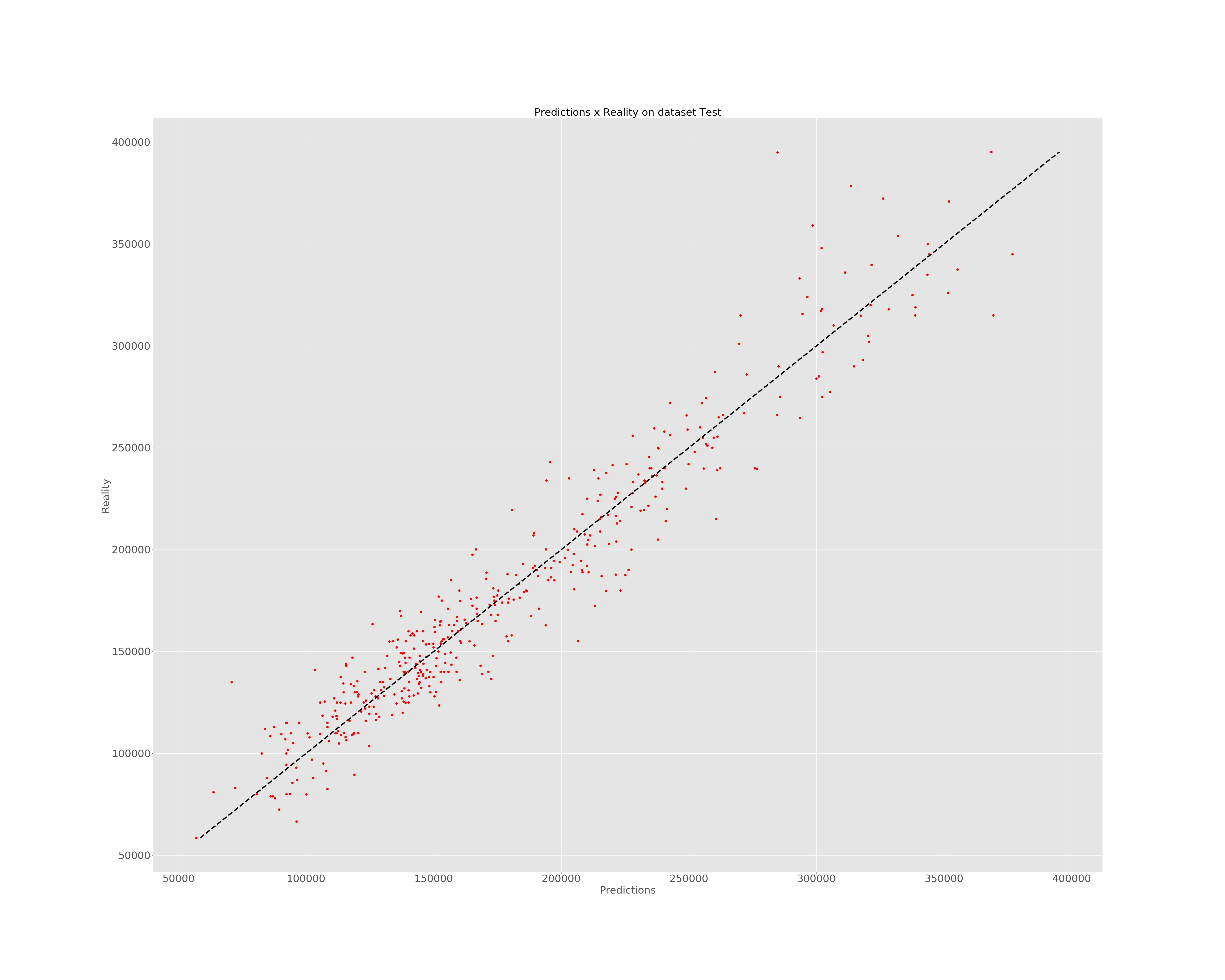
Shallow Network
In this model, we try a activation function with 1000 units.
# Model
regressor = tf.contrib.learn.DNNRegressor(feature_columns = engineered_features, activation_fn = tf.nn.relu, hidden_units=[1000])
# Deep Neural Network Regressor with the training set which contain the data split by train test split
regressor.fit(input_fn = lambda: input_fn_new(training_set) , steps=2000)
ev = regressor.evaluate(input_fn=lambda: input_fn_new(testing_set, training = True), steps=1)
loss_score3 = ev["loss"]
print("Final Loss on the testing set: {0:f}".format(loss_score3))
y = regressor.predict(input_fn=lambda: input_fn_new(testing_set))
predictions = list(itertools.islice(y, testing_set.shape[0]))
predictions = pd.DataFrame(prepro_y.inverse_transform(np.array(predictions).reshape(434,1)))
matplotlib.rc('xtick', labelsize=30)
matplotlib.rc('ytick', labelsize=30)
fig, ax = plt.subplots(figsize=(50, 40))
plt.style.use('ggplot')
plt.plot(predictions.values, reality.values, 'ro')
plt.xlabel('Predictions', fontsize = 30)
plt.ylabel('Reality', fontsize = 30)
plt.title('Predictions x Reality on dataset Test', fontsize = 30)
ax.plot([reality.min(), reality.max()], [reality.min(), reality.max()], 'k--', lw=4)
plt.savefig('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/shallow.jpg')
plt.show()
y_predict = regressor.predict(input_fn=lambda: input_fn_new(testing_sub, training = False))
to_submit(y_predict, "submission_shallow")
Final Loss on the testing set: 0.001733
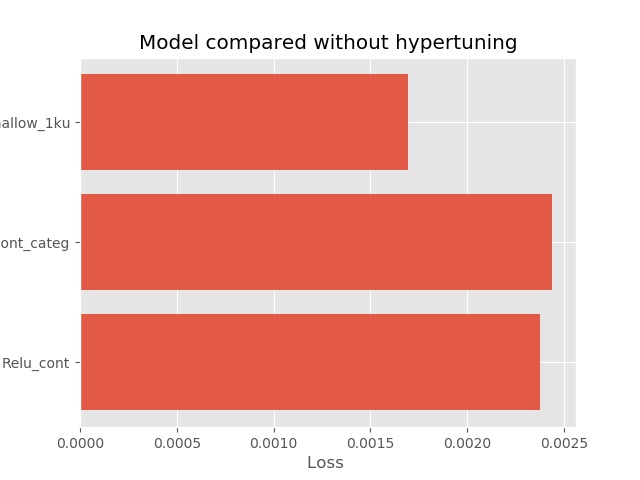
3.Camparion three models
Here we illustrate the score of three models we use above by their score. Intuitivelly for this question shallow network has the least loss.
list_score = [loss_score1, loss_score2, loss_score3]
list_model = ['Relu_cont', 'Relu_cont_categ','Shallow_1ku']
import matplotlib.pyplot as plt; plt.rcdefaults()
plt.style.use('ggplot')
objects = list_model
y_pos = np.arange(len(objects))
performance = list_score
plt.barh(y_pos, performance, align='center', alpha=0.9)
plt.yticks(y_pos, objects)
plt.xlabel('Loss ')
plt.title('Model compared without hypertuning')
plt.savefig('D:/All courses/Data Analysis for Economics(Microeconometrics)/HW6/comparison.jpg')
plt.show()
Result
We export the prediction as csv file. For complete result, click here.
Reference
https://www.kaggle.com/kanncaa1/deep-learning-tutorial-for-beginners